A Guide for
Communities of Interest (COIs)
Implementing the DoD Net-Centric Data Strategy and the Air Force Information
and Data Management Strategy

Version 1.0
April 2005
A Guide for
Communities of Interest (COIs)
Implementing the DoD Net-Centric Data Strategy and the Air Force Information
and Data Management Strategy
Version 1.0
April 2005
The original version of this document was the “COI Handbook”, a technical report prepared by The MITRE Corporation in December 2004. The COI Handbook was prepared as an activity of MITRE’s Enterprise Systems Engineering Office, and also as a part of MITRE’s support to the Air Force Chief Information Officer. Its purpose was to provide additional description and explanation of both the DoD Net-Centric Data Strategy (NCDS), and the Air Force Information and Data Management Strategy (I&DMS). It was intended to offer practical suggestions for discussion and review, and was not intended to take the place of mandatory directives or instructions.
The COI Handbook was distributed on a limited basis to portions of the DoD, the IC, and DHS. It is currently under consideration by the AF Global Force Management (GFM) COI, and by the Time-Sensitive Targeting (TST) COI sponsored by JFCOM (lead by AF/XII).
With minor changes, this document reproduces the content of the COI Handbook. It is issued as an AF document for purposes of information only and is not for mandatory direction or instruction.
Section Page
Introduction.................................................................................................................................................................... 5
1.1 Purpose...................................................................................................................................................................... 5
1.2 Scope........................................................................................................................................................................... 6
1.3 Reference Materials........................................................................................................................................ 6
Background...................................................................................................................................................................... 7
2.1 Community of Interest Characteristics............................................................................................ 7
2.2 Mapping to DoD Net-Centric Data Strategy..................................................................................... 8
2.3 Terminology.......................................................................................................................................................... 8
2.3.1 Community of Interest....................................................................................................................................... 8
2.3.2 Data Asset........................................................................................................................................................... 9
2.3.3 Metadata............................................................................................................................................................. 9
2.3.4 Taxonomy............................................................................................................................................................ 9
2.3.5 Vocabulary......................................................................................................................................................... 9
Tasks and Responsibilities.................................................................................................................................. 10
3.1 Shared Vocabulary........................................................................................................................................ 10
3.2 Shared Information Space......................................................................................................................... 11
3.3 Information Owners and Data Producers..................................................................................... 12
3.4 Practical Considerations.......................................................................................................................... 13
Implementation Guidance...................................................................................................................................... 17
4.1 COI Lifecycle......................................................................................................................................................... 17
4.1.1 Exploration Spiral........................................................................................................................................... 18
4.1.2 Implementation Spiral.................................................................................................................................... 20
4.1.3 Operations Spiral............................................................................................................................................ 23
4.2 Implementation Checklist......................................................................................................................... 23
Case Study........................................................................................................................................................................ 25
5.1 METOC Community of Interest................................................................................................................. 25
Conclusion...................................................................................................................................................................... 30
Integration and interoperability are major focuses for the Department of Defense (DoD). According to the DoD’s Net-Centric Data Strategy (NCDS),
Across the Department of Defense, broad leadership goals are transforming the way information is managed to accelerate decision-making, improve joint warfighting, and create intelligence advantages… Net-centricity compels a shift to a ‘many-to-many’ exchange of data, enabling many users and applications to leverage the same data – extending beyond the previous focus on standardized, predefined, point-to-point interfaces. Hence, the net-centric data objectives are to ensure that data is visible, available, and usable – when needed and where needed – to accelerate decision cycles.
The NCDS goals include making data visible, accessible, understandable, trusted, and interoperable. These goals require methods of providing data discovery, machine interoperability, security, context, pedigree, and quality. They especially require an improved understanding of the meaning of data, so that users and programmers will correctly interpret data as it crosses system and organizational boundaries.
The NCDS recognizes that it is not feasible to establish a single standard meaning of all data for the entire DoD. Some of the goals for data, including the goal of semantic understanding, will be pursued by a number of smaller groups within the DoD, called communities of interest (COIs). The NCDS definition of COI is “the inclusive term used to describe collaborative groups of users who must exchange information in pursuit of their shared goals, interests, missions, or business processes and who therefore must have shared vocabulary for the information they exchange.”
The purpose of this document is to provide specific and practical implementation guidance for COIs as they implement the NCDS. Every COI requires a shared vocabulary for the information to be exchanged. How should this vocabulary be represented, and how is it to be developed? Every COI depends on some form of shared information space to make information available to users. How should these infospaces be implemented and controlled? Every COI requires data producers to create and post the information to be shared. What are their responsibilities to the rest of the community?
COI implementation guidance is provided in two ways. First, the typical COI tasks are described within a framework of three major COI activities related to information management: developing a shared vocabulary, defining a shared information space, and identifying and outlining the responsibilities for information owners and data producers. Second, guidance is provided by highlighting the lessons learned from existing COIs.
This document is concerned with practical guidance for COIs implementing the NCDS. The guidance is aimed at all defense-related COIs, including those in or spanning DoD, the Intelligence Community (IC), and the Department of Homeland Security (DHS). It will be most valuable to the long-lasting institutional COIs; quick-forming, short-term expedient COIs may find that many parts of the guidance do not apply to them.
At the time of this writing, several COIs were being established to address major areas of interoperability and data sharing across DoD; e.g., Global Force Management (GFM COI). These COIs and others would benefit from implementation guidance and from lessons learned with existing COIs.
This report does not address COI issues that are not related to the NCDS, such as shared mission, weapons platforms, operational practices, or communications media. It does not address topics such as when and under what authority may COIs be established, relationship to contracts and programs, governance processes, or synchronization between COIs. These are important considerations but beyond the scope of this document.
There are a number of sources that provide additional information about COIs.
OSD/NII, “Communities
of Interest in the Net-Centric DoD Frequently Asked Questions (FAQs),”
Memorandum by James Roche, “Air
Force Information and Data Management Strategy Policy,”
Memorandum by John Stenbit, “Department of Defense Net-Centric Data Strategy,”
Memorandum by John Stenbit, “Department
of Defense (DoD) Net-Centric Data Strategy: Visibility - Tagging and
Advertising Data Assets with Discovery Metadata,”
The DoD Net-Centric Data Strategy states, “The data vision is predicated on several key elements: (1) Communities of Interest to address organization and maintenance of data…”
There have been inconsistent implementations of the COI concept with varying degrees of success. The intent of this handbook is to leverage the best practices from the success stories and capture the lessons learned from the failures to provide guidance to the DoD and minimize the “re-invention of the wheel.”
· COIs are comprised of people first; then shared vocabulary definitions and information system. We refer to the people as members of the COI.
· COIs have shared vocabularies in subject-area domains. The people in a COI understand that vocabulary. They exchange information about the subject domain. They accomplish this by sharing data that has definitions, which conform to that vocabulary. That data may be structured or unstructured; interpreted by machines or displayed to people.
· The COI concept is very broad and covers a range of potential groups in terms of type and size. There may be many people in a COI. They may not all be explicitly aware that they are part of that COI.
· The number and types of members will change during the lifecycle of the COI. A chartering process may be a mechanism to solicit the appropriate membership.
· The members of a COI often won’t all be in the same organization. Instead, they will often have different reporting relationships and constraints.
· Typically, most of the members won’t be involved in developing the COI’s shared vocabulary. Those few people who work on the COI vocabulary are part of the COI, not the whole COI.
· There may be a person in charge of the COI vocabulary development effort. We call that person the COI vocabulary manager. He does not control the COI, but only the process of creating its vocabulary.
· The COI members use information systems, or build systems, or determine the purposes of the systems to be built.
· We might say that a system is in a COI, but what we really mean is that the users and builders of that system are in the COI and need to use its vocabulary.
· People and systems will often be in more than one COI.
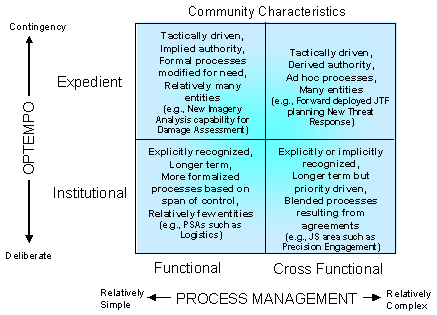
The DoD Net-Centric Data Strategy
characterizes COIs as functional vs. cross-functional and institutional vs.
expedient. Figure 1, from the DoD Net-Centric
Data Strategy, illustrates the characteristics of COIs. Institutional COIs tend to be continuing
entities with responsibilities for ongoing operations. Expedient COIs are transitory and ad-hoc,
focusing on contingency and crisis operations.
They may also be formed to quickly address a specific interoperability
need or capability.
The DoD Net-centric Data Strategy defines COI as “the inclusive term used to describe collaborative groups of users who must exchange information in pursuit of their shared goals, interests, missions, or business processes and who therefore must have shared vocabulary for the information they exchange.” Every task group or collection of people with a declared, common interest could be a COI.
The DoD Net-centric Data Strategy defines a data asset as “any entity that is composed of data. For example, a database is a data asset that comprises data records … data asset means system or application output files, databases, documents, or web pages. Data assets also include services that may be provided to access data from an application.”
Data is used as metadata whenever, relative to some viewpoint, it provides underlying descriptive information or context for other more primary data. Metadata can be used to describe the format, structure/organization, context, business rules, or meaning of data. A typical purpose of metadata (i.e., the underlying descriptive information) is to support data interoperability. Typically, metadata is used to help discover, locate, understand, interpret, convert, render, protect, or manage, some more primary data.
A taxonomy is a categorization or classification scheme that a COI uses to group and relate its data assets.
A common vocabulary represents a community’s shared understanding of the terms they use to define data within their subject area of interest. A vocabulary may include text dictionaries, taxonomies, ontologies, data models, and data element definitions. Well constructed vocabularies support a number of uses, including machine-to-machine (M2M) data exchanges.
Section 3
The tasks performed by COIs as they implement the NCDS (and the associated responsibilities) can be grouped into three major categories. These three categories are: developing a shared vocabulary, determining the shared information space (including services), and identifying the information owners and producers. They represent a straightforward framework in which to examine the activities in COIs.
COI information sharing occurs at the intersection of these three categories. The producers post data to a shared information space, the consumers and applications access that data, and producers and consumers together have the same vocabulary defining that data. As our case studies will show later in this document, successful COIs may emphasize these three categories more or less, depending on the life-cycle and maturity of the COI. Nevertheless, it is fairly straightforward to examine a particular COI, and assess their processes and effectiveness against these three categories.
A common vocabulary represents a community’s shared understanding of terms. People may have different uses for this compatible understanding. For example, some may be concerned with architectural descriptions of information, while others may care about implementing a machine-level data exchange. As a consequence, community vocabularies may not be alike in their level of detail. The fundamental purpose is still always to establish a compatible understanding of terms.
It is almost always necessary to record a community vocabulary in some tangible format. Communities need this documentation to help teach new members what they need to know about the common vocabulary. They need it to remind current members of what they need to know. They need it to support tools that help the members do their jobs – which could be describing desired information flows, or discovering new information, or implementing application-level exchanges, or understanding the information they receive each day.
Adopting or developing a shared vocabulary is an essential purpose of each COI; that is, recognizing that each COI is part of a semantic community. The community’s shared vocabulary is essential for the remaining two categories in this section. Information owners cannot be governed without the appropriate terms to describe the data they produce. A shared information space cannot be developed without a description of the data consumers are allowed to access. Finally, machine-to-machine data exchanges cannot be implemented unless supporting programmers understand the data the same way.
The shared vocabulary and semantic agreement is critical to the success of the COI. Each member of the COI brings an individual view of the problem area, vocabulary, and established data. These must be analyzed to identify the intersecting core set of data elements that are important for members of the COI. The identification of these core data elements, their definitions and associated attributes and relationships constitute a consolidated data model for the COI. Relating data elements of individual systems and interfaces to this consolidated model moves the COI closer to the net-centric vision of many-to-many interfaces.
Members of a COI require a way to exchange information. In the NCDS, this is accomplished through a shared information space (infospace), which may include a set of established services. A shared information space is a collection of data intended to suit the needs of a group of consumers. Data producers post data to one or more infospaces; data consumers pull the data they need from infospaces.
Infospace governance concerns decisions about the infospace contents and the consumers who access that content. The governing authority controlling these decisions may vary. Some infospaces have a single governing authority, typically the commander for whom all the consumers are working. In others, several relatively autonomous organizations establish through consensus the authority for their shared information space.
Each infospace has an executive agent, who typically exercises some form of control over the IT resources that implement the infospace (systems, networks, etc.). This infospace controller executes the decisions of the infospace authority: control over which producers are allowed to post to the infospace, what kinds of data they may post, the frequency at which they may post data, which of these sources will be authoritative for the infospace consumers, and how the infospace data should be organized for navigation and discovery. The infospace controller must also enforce the access control policies set by the infospace authority. This includes establishing the roles for role-based access, their privileges, and the assignment of roles to individuals. Finally, the infospace controller establishes priorities for consumers and arbitrates their conflicting quality-of-service demands.
The defining aspects of an infospace are: the data content, the governance process, the infospace controller, and the consumers subject to that authority. Implementation is not a defining aspect – there are several possible “styles” of infospace implementation:
· a single physical database (or enterprise data warehouse)
· a distributed database
· a federation of semi-autonomous databases
· a peer-to-peer data sharing network
· a publish-and-subscribe message-passing network (with or without persistence of the shared data)
These styles are not mutually exclusive. A particular infospace might be implemented using some combination of these styles.
Even in cases where the infospace does not include persistent data, there still needs to be a definition of shared information for the COI and the mechanisms by which this information shall be exchanged between members (for example, web services). The definition of infospace presented here encompasses three different scenarios: where persistent storage is handled separately from the producing systems, where persistence is handled by the producing systems, and where there is no persistence at all.
As indicated above, the common data model is required to provide a shared infospace and/or access services for members. In the cases of legacy systems, a single adaptor can be written to provide the agreed data for access or discovery by many interfacing systems. Web services and XML can be provided to interfacing systems via the adaptor while hiding particular details of the legacy system. In the case of a shared infospace, the common data model will drive the definition of services that producers and consumers use to access the infospace.
COIs require information owners and data producers, because there cannot be any actual information exchange unless somebody produces some data.
Information owners are organizations that control decisions about data: what data must be collected, how it will be represented and stored, how it will be validated, the degree of accuracy, precision, and other quality factors that will be maintained in the collected data, when it will be released, who is allowed to access and update it, etc. Information owners acquire and operate information systems to effect these decisions. They may delegate this responsibility to subordinate organizations.
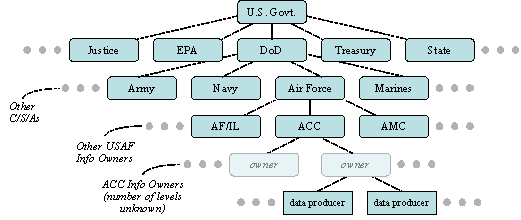
Data producers are the information owners that are finally accountable for the data. We might say they have release authority for specified data. Or we can say that they are the leaf nodes in the information-owner tree. Figure 2 below shows a notional arrangement of information owners into a tree. The diagram helps show why we can have trouble over data ownership decisions even though “all data belongs to the enterprise”. As a practical necessity, ownership authority and responsibility must be delegated to low levels in the tree. Organizations often have little influence on information owners in a completely different subtree. This tends to make cross-organizational data sharing more difficult.
An information system is not a data producer; rather, information systems are built so that data producers can fulfill their responsibilities. Individual data entry operators of these systems are not data producers; they are people who work for a data producer.
Effective data sharing requires all three of the above elements: data producers, shared information spaces, and shared vocabularies. We find the greatest sharing success in situations where the three elements overlap perfectly, so that all of the people involved are subject to the same effective authority. However, in practice, most COIs are too complex to allow this perfect alignment. It is instructive to examine the various types of situations that can arise across the three areas of responsibility. We expect to often find the following, as illustrated in Figure 3.
(a) Data producers that post to more than one shared information space
(b) Data producers that must understand more than one COI vocabulary
(c) COI vocabularies that are used in more than one shared information space
(d) Shared information spaces that include data defined in separate COI vocabularies.
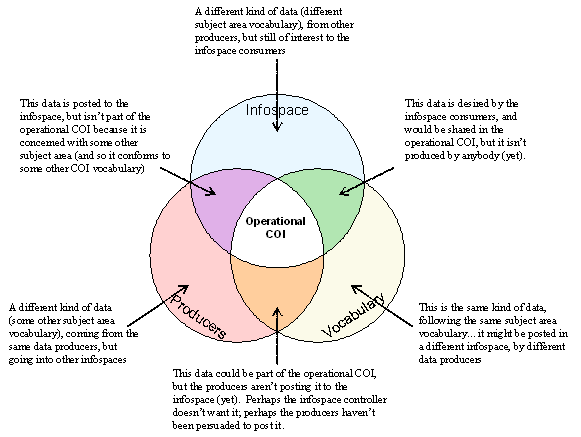
Figure 3.
Intersections in COI Responsibilities
Attempting to establish each COI as a single authority over all of the data producers, the information space and services, and the shared vocabulary process is often undesirable for two reasons: the lines of authority will not align with the existing organizational structure, and the people involved will find themselves subject to multiple authorities, with conflicting demands. We should instead be prepared to establish the lines of authority for data producers in one way, for information spaces in another, and for shared vocabularies in a third. And while we don’t want to continue business-as-usual, we do want the lines of authority to respect the natural “lines of power” in the enterprise. This will reduce the amount of conflict, and place its resolution within a structure best able to make decisions for the benefit of the whole enterprise.
For information owners and data producers, the lines of authority should follow the existing organizational structure. We already have people who are making the decisions and doing the work that information owners make and do. Those people already are accountable within the organization hierarchy. There’s no need to set up something different. What we do need is a process that will make information ownership decisions visible to any interested party, efficiently including and resolving the needs of all stakeholders, so that these decisions are made for the benefit of the entire enterprise.
For each shared information space, the question is: how is the governing authority established, and what is its relation to the infospace consumers? In some cases we will follow the existing lines of combatant command authority or its equivalent in the business mission area, creating infospaces to be governed by the NCA, the CoCOMs, or perhaps lower in the command structure. In other cases we will have more collaborative infospaces established by consensus among autonomous organizations, and governed through a process satisfactory to all. When creating infospaces, the following principle will hold true: distinct groups of consumers for whom no single infospace controller can be established (by command or consensus) require separate infospaces. Over time, examples of successful infospace governance will turn into “templates” suitable for reuse.
For the shared vocabularies, we need a process that allows some to be created with top-down authority, and some to be developed with bottom-up spontaneity. We should therefore allow any group of people to declare a COI. But we should control the naming of all COIs, reserving “blocks” of prominent names for the most important COIs, those formed top-down, with an official charter.[1] For example, we might be happy if a group of users and developers formed an “air mission planning” COI to define a common vocabulary for their systems... but we wouldn’t want to let just anybody declare the “Joint Warfighting COI”. The domains, created by the mission areas, would seem to be a good source of authority for COI charters at the DoD level. DoD Components will probably establish their own source of authority for COI charters at the service level. For example, Air Force policy assigns this authority to its Enterprise Architecture Integration Council (EAIC).
We should expect some arrangements to be made by negotiation between producers and infospace controllers. We will need to form (and record) at least the following two kinds of agreements:
· Availability agreements between a producer and an infospace controller. These describe the conditions under which the infospace controller may rely on the availability of information from the producer. The terms may include effective dates (beginning and ending), measures of data quality, measures of performance, etc.
· Access control agreements between a producer and an infospace controller. These describe access control guarantees made by the infospace controller to the data producer, and/or the terms under which accountability for access control enforcement is transferred from producer to infospace controller.
Section 4
This section provides a list and description of specific activities that should be performed by COIs. This section is intended as guidance. The degree to which these activities are implemented by any particular COI depends on its type i.e., expedient or institutional, its size, and the particular point in the lifecycle of the COI.
We use three activity spirals to describe the activities that COIs must accomplish, in what sequence, and by whom. Normally a COI would start in the exploration spiral, move to the implementation spiral, and finish in the operations spiral. This is illustrated in figure 4. The stages in each spiral correspond to the three areas of responsibility described in section three: shared vocabulary, shared information space, and information owners and data producers.
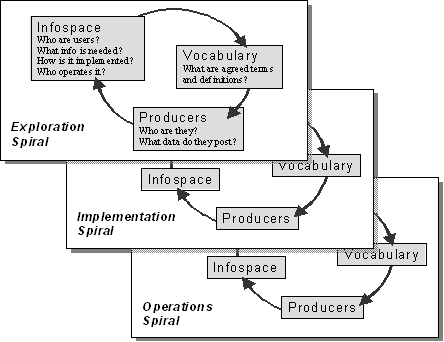
Figure 4. Spiral Model of COI
Lifecycle
This three-spiral model is not intended to be a set process, with a fixed order of events and testable milestones for progress. We expect that COIs will begin at different points, will skip stages within a spiral, will skip steps within a stage, will transition up and down between spirals as needed, and may well follow all three spirals simultaneously.
New COIs may start with any stage. Most will start with the infospace stage. Progress is often made easier by knowing the information needs of the consumers.
Infospace activities
· Identify the information needs that must be satisfied by this COI. What kinds of data will the users expect to retrieve from the COI? Begin with very general descriptions (e.g. “blue force situational awareness information”); these can be refined through subsequent loops through the spiral.
· Also identify the types of information e.g., structured, documents, imagery. Make rough estimates of the anticipated volume of data consumption.
· Identify the consumers of the COI. At first, these will be broad categories of people; in later spirals you may be specific about roles and/or organizations.
· Identify the governance process for the COI. Ask questions such as “who will decide whether a particular person may obtain information from the COI?” and “how will authoritative sources of information be determined?”
· Identify the infospace controller of the COI. There may be more than one.
· It may be useful at this stage to identify the applications used by the COI consumers, if these are large information systems. These systems can be a useful shorthand for describing consumers. (Don’t confuse the applications with the consumers, though.)
· Determine the degree of information integration needed. Is it enough to make the producer’s data available to the consumers in separate results? Or is it necessary to produce one single consistent result? (by correlating data, choosing one of several conflicting results, etc.)
· Decide which of several implementation styles will be implemented: single database, distributed database, federated database, peer-to-peer sharing, message-passing.
· Consider the information security activities that will be needed for the COI consumers and the data they need.
· Do any of the COI consumers need a query capability? This requires some form of persistence in the implementation.
· Do any of the COI consumers need a publish/subscribe capability? This requires some form of subscription and notification mechanism in the implementation.
· Determine who will build the COI implementation. Also determine who will operate and maintain it. Where do these people get requirements and funding? What is the relationship between the maintainer and the infospace controller identified in the infospace stage?
· Consider the information systems used by the data producers (perhaps identified in the previous cycle). Determine how these systems can be adapted to post to the infospace, and where the system builders will get requirements and funding to make these changes.
· Develop data size and usage estimates, including the following items:
o Expected data size and growth for the shared information space.
o Number of concurrent users, peak access times, transaction rates, etc. Make sure adaptors and shared information space can handle the associated loads.
o Network and infrastructure capacity needed to handle data traffic and associated service requests
o Data quality
o Real-time constraints
Vocabulary activities
· Develop a consensus set of terms and definitions to describe the COI information needs. The key word is consensus; all of the people involved in the exploration spiral need a common understanding of the terms. (They do not have to agree that these are the best definitions for the subject area; they only have to agree that they all understand the terms defined.) Collect enough documentation to allow new people to learn this consensus understanding as they join.
· Look for existing vocabularies that may be exploited or reused. These can save work, and may also point you to additional information needs (previous stage), or help you discover additional data producers (next stage).
· At this stage the vocabulary needs are often at the architectural-description level. Consider how the definitions collected can be used in architecture products (e.g. AV-2). Consider how a linkage to architecture descriptions can be maintained in subsequent stages.
Producer activities
· Identify the data producers who could post the information needed by the COI. (Again, it may also be useful to identify the information systems these people use.)
· Determine if any of this information is currently posted to any infospace. Is there any overlap with the COI consumers identified in the infospace stage?
· If fused and/or integrated information is needed, determine who will produce and maintain it. (Fusion adds value, and is thus a producer activity.)
· Examine the current consumers of information identified in this stage; consider whether they belong in the COI, and which activities they should participate in.
COIs are ready to leave the exploration spiral when they are able to describe the consumers, the producers, and the information they share. The shared vocabulary typically will not include implementation-level data models or data element definitions, but it will have enough detail to support a consensus on what those models/elements must cover. The infospace controlling authority will be known. The organization responsible for operating and maintaining the data sharing implementation will be established.
During the implementation spiral the infospace controller and data producers collaborate to form an operational COI at initial operating capability. As before, work may begin with any stage, but will most often begin with the infospace stage.
Infospace activities
Decisions in this stage are made by the infospace controller with oversight from the governance process, which sets the infospace rules to suit the needs of the consumers. Consultation with the data producers is typically required, because the data producers get to decide whether to post their data to an infospace following those rules.
· Determine the consumer-visible interface to the infospace contents, expressed in terms of the questions that can be asked and the answers that will be received. This includes how the infospace contents should be organized for consumer navigation.
· Establish access control requirements:
o Create the list of consumer roles needed to control access
o Define the access privileges of each role (using the common vocabulary to describe the information involved).
o Determine how roles are to be assigned to individual consumers, and make role assignments
· Establish rules for consumer quality-of-service priorities.
· Define specific rules involving data aggregations if needed. (The classic “data aggregation” problem is unsolvable in general. These rules will therefore need to be cast in terms of risk mitigation and risk reduction.)
· Select a set of authoritative sources from the potential data producers; determine which producers are authoritative for what information.
· Where there are unsatisfied information needs, formulate a request for information, directed to one or more data producers – that is, ask some producer to begin collecting the missing information.
· Decide how data will be posted into the infospace. The posting interface is selected by the infospace controller in consultation with the data producers. Implementation choices belong to the builders of the producing systems.
· Implement the producing system interfaces. Legacy systems may be difficult to change, and often must be “wrapped” with adaptors instead. There are several risks. In particular, interface options to the legacy system may be limited, the legacy system may be implemented on obsolete technology with limited tools, and program offices may be reluctant to allow interfaces to the legacy system. Some questions to answer when looking at adaptors:
o Scope the effort and risk of writing the adaptor.
o Where will the adaptor reside. In many cases there are technical and administration reasons to keep the adaptor on the legacy system.
o Determine who will develop the adaptor i.e., is it the team that developed the legacy system or a different group.
o Determine if a suitable test environment be established i.e., how to test the interface to the legacy system. For example, does a separate instance of the legacy system need to be established for testing.
o Determine who will maintain the adaptor once it is written
· Decide how consumers will pull data from the infospace, and implement those interfaces. It is possible that the consumers need nothing more than a web browser. It is also possible that the consumer information systems will have to be modified, or wrapped with adaptors, in much the same way that the producing systems have to be changed.
· Implement the infospace publish/subscribe capability (if one is to be provided).
· Create and maintain discovery metadata catalogs.
Vocabulary Activities
Work in this stage involves the infospace controller (and representative consumers) and the data producers. It is wise to involve subject-matter experts from outside the prospective operational COI (for example, information consumers who are part of a different shared information space). Wherever possible, we want different operational COIs to use the same vocabulary for the same kinds of information.
· Determine how much detail will be required in the COI shared vocabulary. For example, machine-to-machine exchanges require either an implementation-level data exchange model, or an abstract reference model adequate for establishing a semantic match, plus a formal model of the representation details to be mediated (e.g. kilometers to miles).
· Determine how shared vocabulary will be captured and maintained. This includes standards that apply to data definition and modeling, as well as guidelines such as naming conventions, normalization, etc. Possible vocabulary formalisms include:
o ISO 11179 data element definitions
o IDEF1X data models
o UML
o SQL
o XML Schema
o Semantic web languages (RDF, OWL)
· Develop consensus within COI concerning shared data model, data elements, etc. (Again, the COI only agrees that they all understand the definitions; they don’t have to agree that these definitions are all ideal.) Develop new definitions as required; reuse existing definitions where possible; examine the DoD Metadata Registry for existing definitions suitable for reuse.
· Register consensus vocabulary definitions in the DoD Metadata Registry.
· Develop rules by which shared vocabulary updates occur i.e., what governance process will drive updates to the shared vocabulary. Changes to the vocabulary need to be evaluated in terms of impact to the COI systems and users.
Producer Activities
These decisions belong to the data producers, or to their superior organizations within the information owner tree.
· Producers decide what data they will post to the infospace.
· Producers form availability agreements with infospace controller. These describe the conditions under which the infospace controller may rely on the availability of information from the producer. The terms may include effective dates (beginning and ending), measures of data quality, measures of performance, etc.
· Producers form access control agreements with infospace controller. These describe access control guarantees made by the infospace controller to the data producer, and/or the terms under which accountability for access control enforcement is transferred from producer to infospace controller.
· Producers create DDMS-compliant discovery metadata for their data assets, using the shared vocabulary, and enter it in the infospace’s discovery metadata catalog.
COIs are ready to leave the implementation spiral when they reach initial operating capability.
This spiral starts with an operational COI and keeps it running. This is not “maintenance” in the usual sense, because we expect changes to the infospace content and to the information systems that provide it.
Infospace Activities
Actions in the implementation spiral are now updates to the operational COI. The infospace controller, overseen by the governance process, continues to select authoritative sources; organize the infospace contents for subscription, query and navigation; maintain the rules of access control.
· Consumer requests for new information (not currently available in the infospace) are validated, then turned into a request for information to the data producers. The infospace controller may negotiate with information owners (at any level in the information owner tree) for the changes required to produce the new information.
· Consumer requests for improved data quality are also validated and turned into quality feedback for the data producers. The infospace controller may negotiate for quality improvements in the same fashion as above.
· All of the infospace infrastructure – the discovery metadata catalog, persistence capability (if present), publish/subscribe capability (if present), etc. – must be kept running. This requires the usual attention to backup, failover, disaster recovery, and capacity growth.
Vocabulary activities
· Requests for new information may require additions or changes to the shared vocabulary.
Producer activities
· Producers operate their information systems to produce and post data to the infospace according to the terms of their availability agreements.
· Producers ensure that their data is “tagged” with appropriate discovery metadata, entered in the COI catalog.
The checklist of implementation items is organized by the three major areas of responsibility discussed previously. This is presented in Table 1. This checklist is intended as a tool that COIs can apply throughout their activities. Depending on the scope and type of COI, specific items will be more or less relevant.
Table 1. COI Activity Checklist
|
COI Activities to
Implement |
COI Importance |
Key Actions |
Assigned |
Status |
|
|
High, Med, Low, NA |
Outcomes for Each |
Names/Orgs, Dates |
Working, Deferred, Closed |
|
|
|
|
|
|
|
Developing Shared
Vocabulary |
|
|
|
|
|
Develop Common Data Model |
|
|
|
|
|
Vocabulary Update Process |
|
|
|
|
|
Vocabulary Representation(s) |
|
|
|
|
|
Define Data Access and Processing Rules |
|
|
|
|
|
Identify Types of Information |
|
|
|
|
|
Review Data Model against DDMS |
|
|
|
|
|
Identify and Reference Other Data Models |
|
|
|
|
|
Cross-Reference Architecture Products |
|
|
|
|
|
Referenced Published Materials |
|
|
|
|
|
|
|
|
|
|
|
Shared Information
Space and Services |
|
|
|
|
|
Determine How Information Will be Persisted |
|
|
|
|
|
Determine Data Posting Mechanisms |
|
|
|
|
|
Determine Data Sharing Mechanisms |
|
|
|
|
|
Determine How Data is Made Visible |
|
|
|
|
|
Determine Pub/Sub Mechanisms |
|
|
|
|
|
Create Discovery Metadata Catalogs |
|
|
|
|
|
Determine Key Interfaces Between Systems |
|
|
|
|
|
Develop Data Size and Usage Estimates |
|
|
|
|
|
Identify Legacy Systems That Need Adaptors |
|
|
|
|
|
Determine Approach for Adaptors |
|
|
|
|
|
Migrate Private Data to Shared Spaces |
|
|
|
|
|
|
|
|
|
|
|
Information Owners
and Data Producers |
|
|
|
|
|
Identify Authoritative Data Sources |
|
|
|
|
|
Determine Policy for Protecting Data |
|
|
|
|
|
Establish Rules for Role-Based Access |
|
|
|
|
|
Assign and Administer User Roles |
|
|
|
|
|
Control Quality of Service to Consumers |
|
|
|
|
|
Manage Shared Infospace |
|
|
|
|
|
Manage Authoritative Sources |
|
|
|
|
|
Provide Feedback to Data Producers |
|
|
|
|
|
|
|
|
|
|
|
Other |
|
|
|
|
|
Incorporate in Acquisition Processes |
|
|
|
|
|
Register COI Artifacts |
|
|
|
|
|
Identify Cross-COI Exchanges |
|
|
|
|
The
Department of Defense METeorological and OCeanographic (METOC) Community of
Interest was formed in the mid-1990s.
The Navy, in partnership with the Air Force as well as the Army,
sponsored a long-term data definition and data modeling effort in order to
arrive at a comprehensive set of data definitions and logical data models,
standardized across DoD, covering data common to the Joint METOC
community. Data interoperability was a
key objective. At its inception, and for
the next several years, the Joint METOC Data Standards Working Group (DSWG) was
chaired by Mr. Thomas Nabors of CNMOC (Commander, Naval Meteorology and
Oceanography Command) located at
There are usually several formal meetings per year, with a published agenda adhered to. The early years of the DSWG were focused on drafting a series of logical data views (done in part to keep the scope of each scheduled working session manageable), and on defining the component data tables and underlying data elements in a central dictionary. After more than four years of effort, this DoD-wide initiative produced a common, standardized Joint METOC Conceptual Data Model (JMCDM). The JMCDM consists of a central repository containing about 125 logical data views, 600 data tables, and a dictionary providing precise definitions for over 3000 data elements. Development of the JMCDM was facilitated by the pre-existence of a shared vocabulary amongst DoD weather “geeks”. It is also worth noting that much of the data modeling effort by key individuals came “out of hide” with minimal explicit budget support. The CNMOC organization also hired a local contractor to provide a modest level of support.
With the JMCDM established, the Air Force (AFWA) took the lead on drafting a set of implementable physical data models, derived from the JMCDM. When the first group of physical data models had been drafted, reviewed, and scrubbed by the DSWG, the Air Force began implementing standardized physical databases with a series of acquisition programs. Key database segments implemented to date include weather stations/platforms, conventional observations, text messages/bulletins, gridded analysis/forecast models, and an initial version of imagery.
AFWA also took the lead on drafting a set of standard weather parameters, subsequently scrubbed by the DSWG. These parameters are employed in a DoD-standard Joint METOC Broker Language (JMBL), for using systems to access the physical databases being built. A JMBL specification is another DSWG product. (See sections which follow). A lookup table maps using system requests (written in JMBL) for specific weather parameters to the actual physical database segments and attributes which are implemented. JMBL is to provide insulation between using systems and physical databases, as well as interoperability between applications and databases.
One early lesson learned is that it is particularly important for physical data models with some complexity to be well-scrubbed, standardized, and stable prior to intensive software development getting underway. A similar lesson learned applies to the JMBL specification.
Developing
a common vocabulary
With an understanding of the underlying physical data
models, an abstraction layer was created in the form of a set of XML Schemas to
represent the M2M request and response interchanges between systems. This layer
is called the Joint METOC Broker Language (JMBL), alluded to above, and it
defines an XML representation for describing and requesting weather data
products with a strong association and mapping to the individual physical data
models. Within the context of JMBL the differences between the physical data
models were “normalized” such that, for example, an air temperature parameter
is called “temperatureAir” even
though it may be mapped to a surface air temperature stored in a surfaceObs table in a temperatureAir column or as an upper air
temperature observation within an upperAirLevelObs
table. Besides normalizing the names, the units were likewise normalized such
that temperatureAir is represented as
degrees Kelvin to the user in requests and responses regardless of whether the
physical model uses Celsius, Fahrenheit, or Kelvin. A mirror structure in XML
was created for each data class (imagery, observations, etc.) with a generic
set of parameters and values to represent the metadata and data.
Business rules and implementation guidance beyond the common vocabulary have not yet been defined at the COI level, and various implementations are filling in the gaps with respect to interpretations of optional elements and co-dependencies between XML elements and attributes. This leads to clients not being able to interoperate with different service providers without a detailed knowledge of what each service does differently. A shared vocabulary isn’t sufficient for application / database interoperability if consumers and data providers span multiple organizational services, as does the METOC COI. Shared business rules, reference implementations, and development forums are needed to ensure the M2M interfaces are actually interoperable. A shared vocabulary does, however, make exchanges of weather products between COI members valuable. To achieve full interoperability, the COI should stress interoperability and use automated tools to test their interfaces, following strict interoperability rules; e.g. Web Services Interoperability (WS-I) Basic Profiles.
The XML Schemas must be consistent from day one and follow the appropriate XML Schema best practices; e.g., Department of the Navy XML Developer's Guide, Federal XML Developer's Guide, etc. The earlier JMBL 2.x schemas had inconsistencies (e.g. no common element/type/attribute naming conventions) added over a long period of time. These inconsistencies combined with the complexity of the vocabulary made maintenance and understandability difficult. This earlier schema did not follow some of the XML Schema recommendations in the listed best practice documents. For example, the JMBL 2.x specification defined an enumerated list of all possible weather parameters, but this list was very large (over 900 items) and changed on a monthly basis, making a service implemented against an earlier version incompatible with a client using the newer version. The enumerated list was changed to an unrestricted string type to allow the service to define the values at runtime. Great effort has been made to overhaul this XML Schema into a new version of JMBL (3.0) that breaks backwards compatibility in order to achieve the goals of greater consistency, extensibility, and interoperability to the common language.
Shared
Infospace
The current mechanism to retrieve data is by synchronous request/response exchanges with SOAP over HTTP(S) and FTP with some point-to-point publish/subscribe services implemented at each echelon. Data is staged and ingested at each echelon from various sensors and data providers, some of which have adapters to convert proprietary formats and representations into the common vocabulary. A related Joint METOC Input Broker Language (JMIBL) is used to validate and ingest data products, with its own web service, adding the data products to physical database instances. Publish/subscribe and data dissemination (legacy) mechanisms exist throughout the METOC community with the Weather Product Management and Distribution System (WPMDS) in the Air Force and Tactical Environmental Data Services (TEDServices) in the Navy systems, however, they do not use a common vocabulary interface (broker language). More sophisticated and standardized publish/subscribe services will be added in later increments, most likely by extending JMBL.
A common vocabulary with respect to weather data, and a set of XML Schemas for data exchange, has been created by the METOC community. However, with respect to web services, a common web services definition language (WSDL) has not yet been defined. Several data providers have created their own WSDLs, making the bindings to implementations of the services not interoperable among clients that must work with a particular data provider’s implementation. If web services will be used to exchange data, and interoperability is desired, then a baseline WSDL is required to define common web services and how the common vocabulary is mapped to a given service.
Information
ownership and data producers
Within the Air Force, the METOC community has a hierarchy of ownership and data producers where a global view is maintained and created by the strategic centers (AFWA and AFCCC), an operational/theater-level view by 12 Operational Weather Squadrons (OWS) worldwide, and a tactical view by nearly 400 Combat Weather Teams (CWTs) distributed around the globe including Army sites. These echelons are clearly defined in the enterprise architecture products (OV-1, SV-1, etc.). Data is produced and consumed at each level and shared across the enterprise. The Navy has an analogous organization, and exchanges major weather products with the Air Force.
Next steps
A virtual infospace is being evaluated to abstract the separate existing infospaces and data stores into a single virtual access point where consumers do not need to discover all the various weather data providers available, but can contact one and have a query distributed and routed to the appropriate data provider.
The challenge for the community is getting the appropriate METOC information from the right source to the right customer across the entire Department of Defense (DoD) Global Information Grid. Presently, numerous sources and interfaces exist to address this challenge. As illustrated in figure 4, tomorrow’s vision is to organize a DoD-standardized capability that expedites delivery of data between METOC sources and C4ISR/MP system customers. Collectively these METOC sources are referred to as the “4-D data cube” or the Joint METOC Data Base (JMDB). The JMDB is a distributed data environment that enables the METOC information to be discovered and queried.
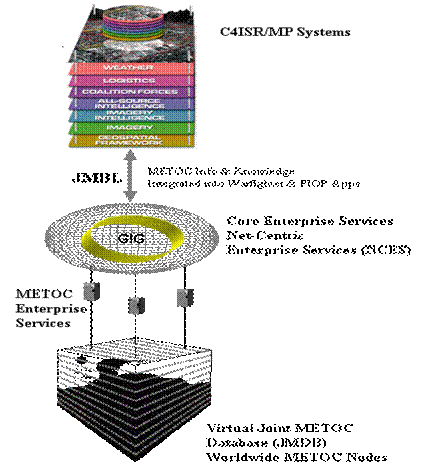
Figure 4.
Net-Centric METOC Operations
Section 6
Work to implement the DoD Net-Centric Data Strategy is occurring on many different fronts, from efforts within individual programs to cross-cutting activities in the services and across the DoD. The OSD/NII Net-Centric reviews and use of the Net-Centric checklist establish specific criteria with which programs can assess their current and future capabilities in meeting net-centric tenets. COIs are a key mechanism in this process, and in helping programs make progress in the Net-Centric data goals e.g., make data visible, accessible, understandable.
There are significant challenges around governance, cross-COI synchronization, and tying COIs to contract language and direction. These topics will receive considerable attention across DoD in the coming years. In the mean time, we expect that COIs will take on many different forms and fundamentally need to address the core technical and management issues outlined in this document.
[1] This might resemble the convention for creating usenet newsgroups. Anyone can create a newsgroup in the alt.* hierarchy. There is an approval process for creating newsgroups in the main hierarchies.